-
Convolutional Neural Networks - 2 weekGoogle ML Bootcamp 2022/Coursera mission 2022. 7. 27. 14:32
Why look at case studies?
pool, conv와 같은 레이어를 어떻게 CV에서 사용하는지 배우는 좋은 방법은 예시를 보는 것이라고 한다
따라서 몇 가지 CNN 연구 사례를 살펴볼 것이다
어떤 문제에 잘 작동하는 신경망 아키덱쳐는 다른 CV task에도 보통 잘 작동한다고 한다 (마법?)
아무튼 다음 영상들에서 이런저런 아키텍처를 볼 것이다
요약해 주셨는데 차피 기억 못할거 아래서 자세히 알아보자
Classic Networks
LaNet-5, AlexNet, VGNet과 같은 고전 신경망을 배워보자
LaNet-5
지난 주차에 본 모델과 유사하다
손글씨 인식 모델이 아래와 같이 구성 된다

마지막 출력층에선 지금은 사용하지 않는 이상한 활성 함수를 사용했다고 한다
논문을 발표한 1998년도에는 패딩을 사용하지 않아, conv에서 크기가 줄어든다최근 신경망에 비해 모델 크기가 작다
과거 모델에 사용된 점도 설명해 주셨는데, 필요하면 찾아보자.
AlexNet
논문 첫 저자의 이름을 딴 모델이다

LaNet과 비슷하지만 크기가 훨씬 커졌다
라넷은 6만 개 정도의 파라미터가 있지만, 알렉스는 6천만 개 정도의 파라미터가 있다
마찬가지로 예전에 쓰다가 사용하지 않는 고대의 마법은 넘어가자
VGG-16
많은 파라미터를 가지고 있는 대신, 더 간단한 네트워크로 conv에 집중하는데 초점을 맞췄다
conv는 3x3 필터와 s=1, same conv로 pool 은 2x2의 max pool로 하며 s=2로 통일시켰다

모델이 깊기에 그림은 생략하고, x2는 conv 2번 적용시키기라는 뜻이다 모델이 깊기는 하지만 아주 균일하고 단순해 보인다
conv가 반복되며 채널이 2배가 되는 점에도 주목하자 (아키텍처 설계에 사용된다고 하는데 왜인지는 모르겠다. 마법이네)
이렇게 모델이 균일한게 연구자들에게 굉장히 매력적이라고 한다 (대체 왤까)
채널이 늘지만 pooling으로 크기가 절반이 되는 것처럼 균일한게 논문의 매력이라고 하신다 (🤔 그런가 보네~)
ResNets
아주아주 깊은 모델은 vanishing과 exploding gradient과 같은 문제가 발생하기에 학습이 쉽지 않다
한 레이어의 activation을 가져와 더 깊은 다른 계층에 전달할 수 있는 방법을 배워보자
이를 이용하여 ResNets을 구축하여 깊은 모델도 학습 가능하다
ResNets은 Residual block으로 이루어져 있는데 이게 무엇인지 알아보자
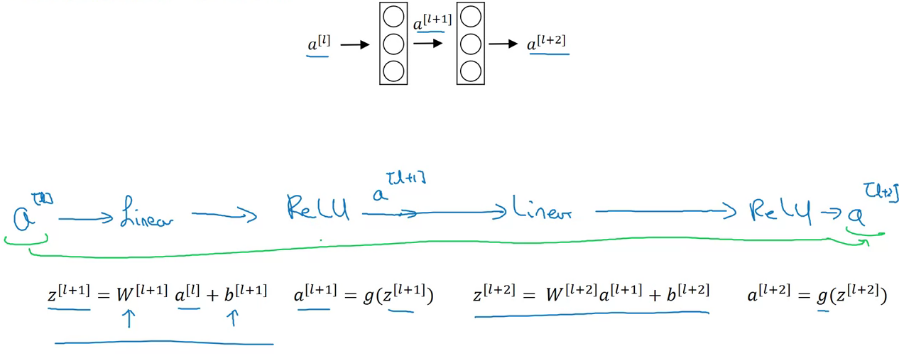
\(a^{[l]}\)이 \(a^{[l+2]}\)가 되기 위해선 위의 파란색의 일련의 과정을 거쳐야 하는데, 이를 레이어 세트의 main path라고 하자

그림에선 파란색, 아래 도표에선 보라색 ResNet에선 \(a^{[l]}\)을 복사해와 비선형 함수를 적용시키기 전 신경망에 매치시켜준다
이를 Short cut 혹은 skip connection이라고 한다
파란 길을 통과하는 대신 보라색을 통해 빠르게 깊은 레이어에 접근할 수 있다
젤 아래 파란색으로 표시된 식에 \(a^{[l]}\)을 더한게 residual block을 만들어 준 것이다
ResNet은 이러한 residual block을 많이 사용하여 더 깊은 모델을 학습 가능하게 만든다
예시를 보며 알아보자

파란색 선을 통해 5개의 residual block을 만들어 주었다 만약 short cut이 없다면, 그냥 plane network이다 (ResNet 논문에서 나오는 단어라고 한다)

초록색이 이론 값, 파란색이 실제 이론상 레이어 수가 늘어날수록 훈련 에러가 줄어야 하지만, palne network에선 줄어들다가 다시 늘어나게 된다 (vanishing, exploding.)
ReNet은 더 깊은 신경망을 학습 가능하도록 도와준다
Why ResNets Work?
ResNet이 뭔지도 알겠고, 도움을 주는 것도 알겠다
근데 이게 왜 깊은 신경망을 학습할 수 있도록 도와줄까?

residual block이 추가되고 무슨 일이 일어나는지 살펴보자 편의를 위해 ReLU 활성화 함수를 사용했다고 하자
\(a^{[l+2]}\)는 위와 같은 식으로 구할 수 있다
그런데 정규화와 같이 \(W,b\)를 규제하게 되면 0과 가깝게 크기가 작아지게 된다
이는 곧 \(a^{[l+2]}\)이 \(a^{[l]}\)과 비슷한 값이 되도록 만든다
(보통 same conv를 사용하기에 차원이 같지만, 아니라면 \(W_s\)를 곱해 차원을 일치시켜줘야 한다)
이는 곧 하나의 residual block이 항등 함수와 비슷한 역할을 하게 만들어 학습을 쉽고, 수행 능력에 도움을 준다고 한다
(강의 보고 조금 더 찾아봤다 ㅎㅎ)
직관적으로 시험을 볼 때, plane net이 오픈북이 불가능한 시험이라면, ResNet은 오픈북 시험이다
즉 ResNet은 모든 내용을 외울 필요 없이, 수업시간에 따로 필기한 내용만 학습하면 된다
기존의 레이어를 통과하는 과정이 y=h(x) 매핑이라면, ResNet은 y=f(x) + x 매핑이다
모든 정보를 새로 학습하는 것이 아니라 기존에 받은, 변하지 않는 x라는 정보를 가지고 있다
그렇기에 학습하기에 학습해야 하는 양이 상대적으로 줄어드는 효과가 있다
ReNet은 f(x) = h(x) - x를 0에 가깝도록 학습시키는 것이 목적인데, h(x) - x을 residual이라고 하기에 residual을 최소로 하는 ResNet이라고 부른다
Networks in Networks and 1x1 Convolutions
아키텍처를 설계하며 1x1 conv는 많은 도움이 된다고 한다
대체 뭘 하는 친구인지 모르겠으니, 뭔지 알아보자
채널이 하나라면 그냥 실수 배 곱해지는 것이니 별 의미가 없어 보인다

그러나 채널이 여러 개라면, 마치 해당 위치의 32개의 입력 값을 가지는 하나의 뉴런을 가진 것 처럼 동작 할 수 있다
필터가 여러개라면, 각각에 적용되는 FC 신경망을 가지는 효과를 가진다
이러한 아이디어를 1x1 conv 혹은 network in network라고 부른다

넓이와 높이는 유지하며 채널 수만 줄였다 1x1 conv이 유용한 위의 예시를 살펴보자
높이와 넓이를 줄이고 싶으면 pooling layer를 사용하면 된다
채널을 줄이고 싶을 때는, 바로 위에서 배운 1x1 conv를 사용하면 된다
물론 1x1 conv는 비선형성을 가지고 있기에 채널 수를 유지하고 싶은 경우에도 사용 가능하다
Inception Network Motivation
레이어를 설계하며 1x3, 3x3, 5x5, pooling 등 다양한 필터 중 선택해야 한다
inception network는 왜 다 따로 해야 할까? 를 말한다
네트워크 아키텍처가 더 복잡해지지만, 매우 잘 작동한다고 한다
어떻게 생겼는지 살펴보자

same conv를 해주었다 그림에서 보이듯이, inception network의 아이디어는 다양한 필터와 pooling 중 하나를 선택하는 것이 아니라
모두 수행하고 이들을 조합하는 것이다
그러나 계산하는데 많은 비용(시간 등)이 든다는 장점이 있다
물론 아키텍처를 설계하는 방식에 따라 차이가 날 수도 있다
5x5 필터를 예시로 계산해보자

위에선 보라색으로 그려져있다 필터의 크기는 5 x 5 x 192이고 32개가 존재한다
출력 크기가 28 x 28 x 32개 이므로, 총 28 x 28 x 32 x 5 x 5 x 192 약 1억 2천만 번 계산이 필요하다
이번에는 1 x 1 conv를 사용하여 연산의 횟수를 줄여보자

1 x 1 필터 16개와, 5 x 5 필터 32 개를 순서대로 적용시키자
가운데 1 x 1 레이어를 bottleneck layer라고 부른다 (volume이 압축되어있음)
위와 동일하게 계산해 보자
28 x 28 x 16 x 192 = 240만, 28 x 28 x 32 x 5 x 5 x 16 = 1000만
총 약 1240만 번 계산이 필요하다
이전에 비해 1/10 정도의 횟수의 연산이 수행되었다
Inception Network
inception network의 구성 요소를 알았으니 구축 방법을 배워보자
5 x 5 필터에 적용한 것을 다른 필터에도 적용시켜보자 (처음에 본 무지개떡 그림처럼)
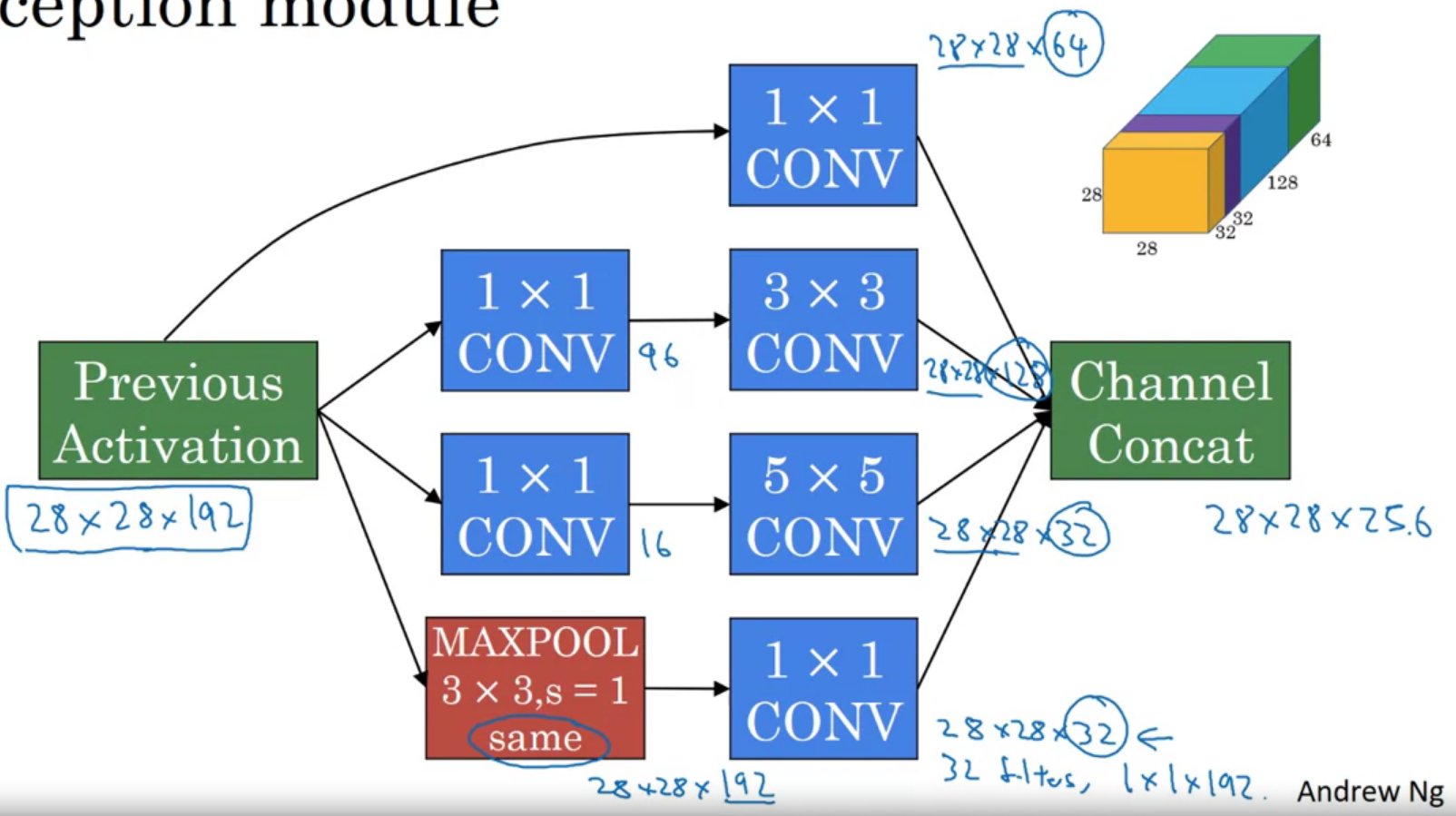
pooling layer의 경우 conv는 채널을 줄이는 역할을 한다
channel concat은 위에 무지개떡 만드는 과정이다
이 과정이 하나의 inception module을 만드는 과정이고, inception network는 이 모듈들의 조합으로 구성된다
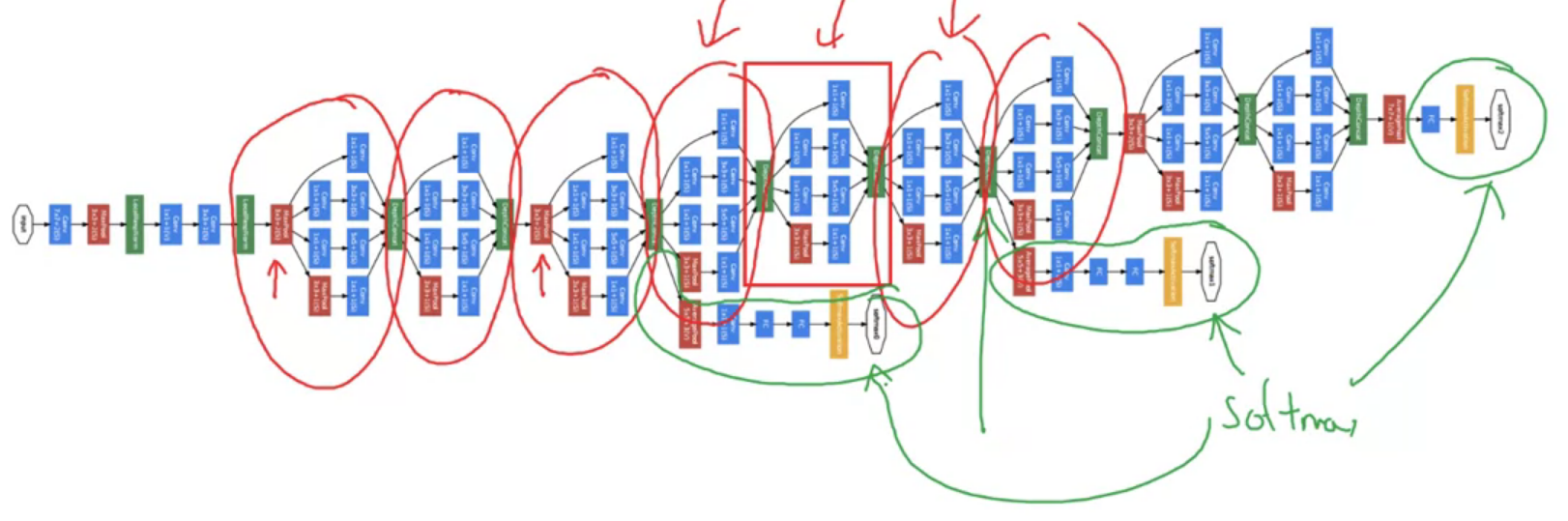
GoogleNet 중간에 초록색으로 표시된 hidden layer를 통해 출력을 예측하는 것은 효과적이라고 한다
정규화 효과도 있어 overfitting도 완화시켜준다고 한다
TMI인데 inception 논문에서 아래 사진을 썼기에 이름이 inception network라고 한다

뭐야 이건 영화 인셉션의 한 장면이라는데, 논문에 정말로 이 사진이 등장한다
MobileNet
CV의 또 다른 기초 conv net 아키텍처를 배워보자
MobileNet은 계산 비용을 줄여서, 휴대폰이나 임베디드처럼 저성능 환경에서도 효율적으로 작동하게 만들어준다
어떻게 생겼는지 normal conv와 Depthwise separable conv를 비교하며 알아보자
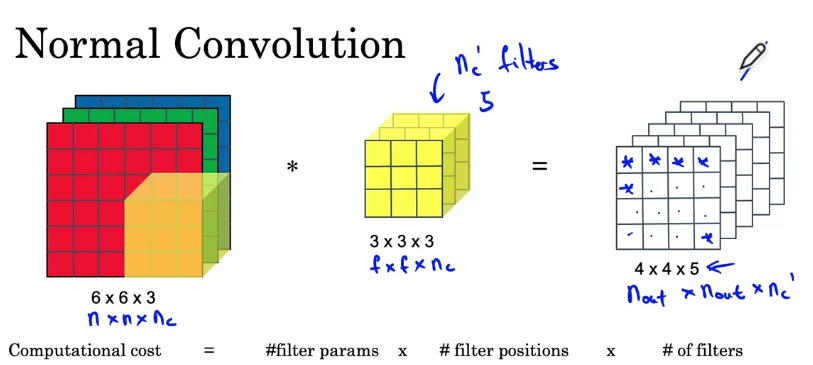
계산 방법은 생략하자 #filter params = \(f \times f \times n_c\), #filter positions = \(n_{out} \times n_{out}\)으로 계산된다
위의 예시에서 숫자를 사용하여 계산하면
(3 x 3 x 3) x (4 x 4) x 5 = 2160이다

depthwise와 pointwise 두 단계를 합쳐서 depthwise separable 단계를 구성한다
과정 별로 계산을 살펴보자
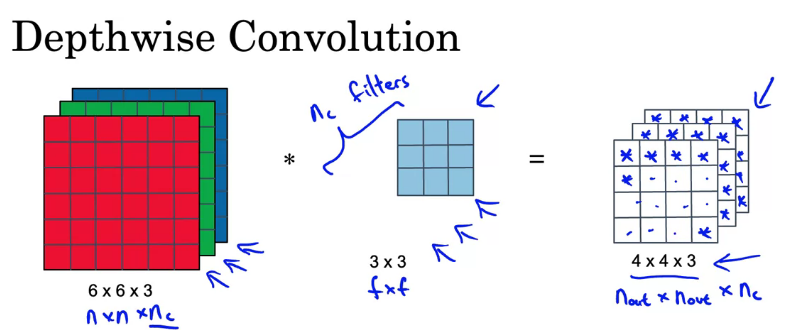
앞선 depthwise conv 부분이다 여러 개의 필터가 아닌 하나의 필터만 적용시키자
위와 동일한 계산을 하면
(3 x 3) x (4 x 4) x 3 = 432이다

pointwise conv 그다음으로 중간 계산 값에 대해 1 x 1 conv를 적용하여 원하는 채널 수로 만든다
(1 x 1 x 1) x (4 x 4) x 5 = 240
두 conv 모두 동일한 입력과, 출력 size를 가진다
그러나 normal conv는 2160번의 연산을, depthwise separable은 총 672번의 연산을 가진다
약 1/3의 비용 절감의 효과가 있다
일반화하면 \({1\over n_c} + {1\over f^2}\) 배의 비용이 든다고 한다 (\(n_c\)는 필터 수 == ouput channel)
보통 output size가 크기에, 채널의 수에 더 크게 영향을 받고 f=3이라면 10배 정도 저렴하다
MobileNet Architecture
값비싼 normal conv를 사용하는 모든 곳에, 비용이 적은 depthwise separate conv를 사용하여 구현할 수 있다
MobileNet v1 모델은 아래와 같은 구조를 가졌다

depthwise separable conv 가 13 레이어 존재한다 시간적으로 이득을 보면서 기존보다 더 나은 성능을 보여준다고 한다
그런데 이를 개선할 수 있다고 하는데 그게 MobileNet v2이다

두 가지 주요 변경 사항이 있다
ResNet에서 배운 Skip connection을 가지고 있다
또한 Expansion layer을 가지고 있다
v2에선 블록을 17번 반복하고, pool FC softmax를 수행한다
이 블록은 bottleneck block라고도 부른다
자세히 살펴보자

사실 각 부분이 말 그대로의 역할을 한다
Res 부분이 존재하여 ResNet과 같은 효용을 얻을 수 있다
1 x 1 expansion이 채널의 수를 늘려 더 풍부한 학습을 할 수 있도록 해준다
depthwise와 pointwise는 위에서 알아봤으니 넘어가자
pointwise에서 메모리 양이 다시 줄어들기에 bottleneck block이라고 부른다
EfficientNet
이런 아키텍처들을 장치에 맞게 튜닝하는 법을 알아보자
기기가 메모리가 크고 성능이 좋다면, 더 큰 신경망으로 정확도를 높이길 바랄 수 있고
반대로 성능이 떨어진다면 작은 신경망을 사용해, 정확성을 희생하며 속도를 키울 수도 있다
이를 위해 입력 이미지의 해상도(resoultion), 신경망의 깊이 (depth), 레이어의 너비(width)를 조절해야 한다
r, d, w를 어떤 규모로 변화시켜야 하고, 뭘 변화시킬지 정하는 것은 쉽지 않다
해당 장치에서 구현한 오픈소스를 열어보고, 배우는게 좋다고 한다
Using Open-Source Implementation
개발하며 오픈 소스를 찾아 시작하는 것은 도움이 된다
깃헙 같은 곳에서 검색하고 쓰자
Transfer Learning
다른 사람이 훈련시킨 네트워크 아키텍처를 다운 받아, pre-train으로 사용하면 더 빠른 학습이 가능하다
누군가가 몇 달 동안 검색해서 열심히 초기화해 둔 것을 오픈소스로 올려둔 것을 주워오자

교수님이 그리신 고양이 귀엽지 고양이를 분류하는 모델을 만든다고 해보자
우린 위에 있는 파란 깜찍이, 빨간 깜찍이, 나머지로 분류하는 클래스 3개가 필요하다
이를 위해 오픈 소스 중 1000종의 멍멍이로 분류하는 모델을 가져온다
그리고 softmax 부분만 파라미터를 조정하여 학습 가능하다 (나머지 레이어는 freeze 하여 trainable parameter가 없다고 고정)
그렇기에 이전 레이어는 변경되지 않아, 학습 속도를 더 빠르게 하기 위해 입력에 따른 출력 값을 디스크에 벡터로 저장해 둘 수 도 있다
데이터가 좀 더 많다면, 앞에 고정시키는 레이어 수를 줄여 정확도를 높일 수 있다
그냥 데이터가 아주 많다면 네트워크 아키텍처만 가져와서 재학습 시켜도 된다
Data Augmentation
뭔가 중복되는게 계속 등장하는 느낌은 기분 탓일까
CV는 데이터가 많이 필요한데, 데이터를 충분히 수집하지 못한 경우가 있을 수도 있다
이때 사용하는 것이 Data Augmentation이다

대칭과 이미지에서 부분 가져오기, 회전, 일그러짐 주기 등등등 많은 방법이 있다
주로 위의 그림이 있는 두 가지를 사용한다고 한다
또한 색상 변경도 자주 사용된다

사진에 빛이 더 비치거나? 그런 느낌의 효과를 줄 수 있다
고양이 자체가 변하는 것은 아니기에 y 라벨링도 그대로다
RGB를 선택 과정에서 PCA color augmentation이라는 AlexNet 논문 방법을 사용한다고 한다 (마법이니 나중에 알아보자)
RB로는 변경이 많고, G는 별로 변경이 없다고 한다
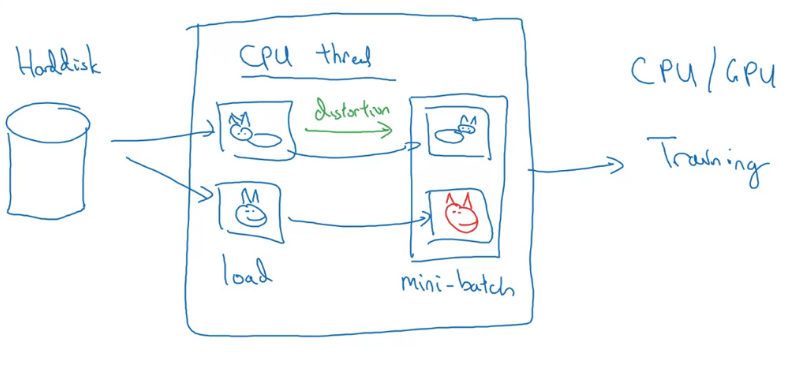
주로 멀티스레드를 활용해, augmentation과 훈련을 따로 한다고 한다
State of Computer Vision
딥러닝은 많은 분야에 성공적으로 사용되고 있다
CV에서의 교수님이 관찰한 몇몇 특징이 있다는데 뭔지 알아보자
라벨링 된 데이터가 많으며, 사람이 수작업 아키텍처를 더 잘 설계하면 모델의 성능이 개선된다
데이터가 많다면, 사실 아키텍쳐를 그냥 단순하게 구성해도 된다
그러나 보통 데이터가 부족하기에 더 복잡한 아키텍처를 만들어야 한다
사람이 직접 hand-engineering을 할 필요성이 늘어난다
또한 데이터가 적을 때는 transfer learning을 학습해도 좋다
잘 작동하거나, 대회에서 우승하는 유용한 팁들이다
- 앙상블 (Ensembling)
여러 네트워크를 독립적으로 학습시키고, output의 평균을 사용하자 - Multi-crop at test time
data augmentation을 적용시키는 하나의 형태로 이미지의 가운데, 각 사분면? 쪽을 쪼개는 건데 궁금하면 찾아보자
공통적으로 실행시간을 키우고, 메모리 사용양을 늘리기도 하기에 주의해야 한다

오픈소스를 쓰자~ 'Google ML Bootcamp 2022 > Coursera mission' 카테고리의 다른 글
Convolutional Neural Networks - 3 week (0) 2022.07.31 Convolutional Neural Networks - 2 week 실습 (0) 2022.07.29 Convolutional Neural Networks - 1 week (0) 2022.07.21 Structuring Machine Learning Projects - 2 week (0) 2022.07.16 Structuring Machine Learning Projects - 1 week (0) 2022.07.16 - 앙상블 (Ensembling)