-
Sequence Models - 3 weekGoogle ML Bootcamp 2022/Coursera mission 2022. 8. 14. 23:56
Basic Models
기계 번역과 음성 인식 등에 사용되는 시퀀스와 시퀀스 모델에 대해 배워보자
먼저 시퀀스 모델이 사용된 예시를 좀 알아보자

기계 번역의 아키텍쳐. many-to-many 아키텍처다 또한 이미지를 보고 설명하는 글을 만들어 내는 image captioning 도 할 수 있다

CNN에서 배운 Alex Net softmax 대신, encoding 된 벡터를 RNN decoder에 넘겨주면 된다
Picking the Most Likely Sentence
시퀀스 기계 번역 모델과, 첫 주에 배운 언어 모델은 몇몇 차이점이 있다

seed에 따른 문장을 생성하고, 멀쩡한 문장인지 판단한다 
기계 번역 모델 보라색 디코더는 위의 언어 모델과 굉장히 비슷하게 생겼다
입력이 영벡터나, 시드인 대신 인코더 네트워크에서 입력을 받는다는 차이가 있다
언어 모델이 p(y) 라면, 기계 번역은 p(y|x)인 느낌?
번역을 무작위로 한다면, 좀 이상한 문장이 나올 수도 있기에 확률을 최대화하는 문장을 찾기 바란다

프랑스어 -> 영어 즉 우리는 해당 확률을 최대화 할 y를 찾는 모델을 제작해야 한다
이를 위한 가장 흔한 알고리즘은 beam search라고 한다
그리디 하게 최대 확률 다음 단어를 계속 선택할 수 있을 것 같지만, 멀쩡히 작동하지 않는다

아래 문장이 그리디하게 선택 한 경우인데, 위의 문장보다 불필요한 단어가 더 많다 단어 수가 늘어남에 따라 문장의 가능성은 기하급수적으로 늘어나고, 효율적인 알고리즘이 필요하다
근사 탐색 같은 방법이 좀 잘 작동한다고 한다
Beam Search
최상의 번역을 찾기 위한 알고리즘 중 빔 서치에 대해 배워보자
먼저 첫 단어를 무엇으로 할지 정해야 한다
그리디가 그냥 가장 확률이 큰 것 하나를 고르는 것과 다르게, 빔 서치는 여러 단어를 대안으로 선택한다
선택하는 단어의 개수를 beam width라고 한다

softmax 상위 B 개를 저장한다 그리고 다음 단어를 선택한다
이때 단순히, 첫 단어 뒤에 올법한 단어가 아닌
첫 단어와 두 번째 단어가 번역에 가장 어울리는 쌍을 선택해야 한다
\(p(y^{<1>},y^{<2>}|x)=p(y^{<1>}|x)p(y^{<2>}|x,y^{<1>})\)
첫 단어에 따라 B*(단어 집합수) 만큼의 실행을 하고, 거기서 또 상위 B 개를 선택한다
이때 첫 단어 별로 하나가 아닌, 그냥 확률 상위 B개를 고른다
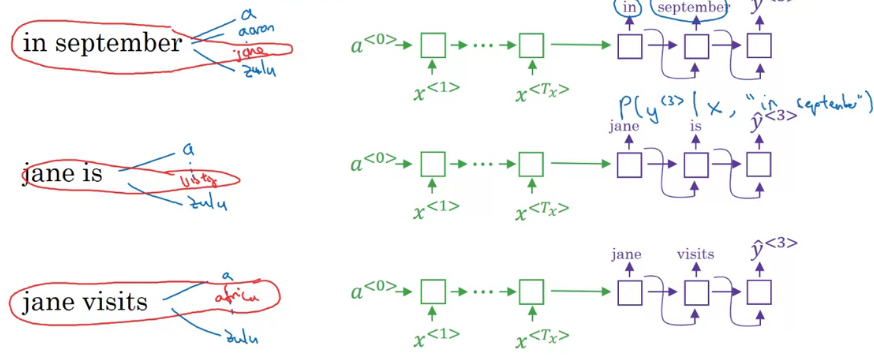
이를 반복한다 Refinements to Beam Search
빔 탐색에 대해 좀 더 알아보자
먼저 Length normalization이란 게 있다
빔 탐색에선 아래 식을 최대화 해야 했다

파이 기호는 곱을 의미한다 그런데 대부분의 항은 1보다 작기에, 언더플로우가 발생할 수 있다
그래서 이 식에 로그를 취하자
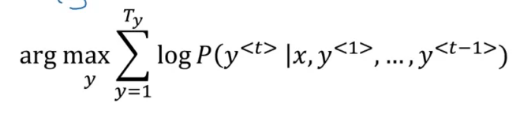
sum에 t=1이 되야 한다 기계 번역에서 1보다 작은 수를 곱하기에, 비정상적으로 짧은 문장을 선호하는 경항도 억제할 수 있다
위 식을 그냥 최대화하는 것보다 길이로 나눠주어 정규화하면 더 좋다고 한다
\(1\over T_y^\alpha\)를 곱해 하이퍼 파라미터로 사용한다고 하신다
\({1\over T_y^\alpha}\sum_{t=1}^{T_y}logP(y^{<t>}|x,y^{<1>}, \dots , y^{<t-1>})\)
Beam width B는 어떻게 선택해야 할까
크게 선택한다면, 선택지가 늘어나 정확도가 올라가지만 느려진다
반대로 작으면 정확도는 떨어지나 빨라지고 메모리 사용량도 줄어든다
1000, 3000으로 선택하긴 한데 어디서 동작시키냐에 따라 다르다
빔 탐색은 BFS, DFS처럼 항상 정확한 최적을 구해주지는 않는다고 한다
Error Analysis in Beam Search
오류 탐색으로 빔 서치의 정상 작동 여부를 판단하는 법을 알아보자

이런 예측을 했다고 생각하자 첫 주에 배운 RNN으로 문장이 자연스러운 확률을 분석하여 케이스 별로 어디에 문제가 있는지 알 수 있다
\(P(y^* | x)\), \(P(\hat {y}| x)\)를 구해준다
먼저 \(P(y^*|x)>P(\hat{y}| x)\) 인 경우
확률을 최대화하는 t 탐색에 실패하였기 때문에
빔 탐색에 문제가 있다
반대로 \(P(y^*|x)\leq P(\hat{y}|x)\)인 경우
더 나은 번역에 대해 낮은 점수를 주었으므로
RNN에 문제가 있는 경우이다
Bleu Score (Optional)
사실 이미지 인식은 개, 고양이 처럼 하나의 정답이 있지만
기계 번역은 여러개의 좋은 정답이 있고, 정확성을 측정하기만 하면 된다Bleu score는 기계 번역이 얼마나 정확한지를 측정하는 점수이다
뭔가 느낌이 사람이 한 번역과 비슷하면 높을 것 같다
Bilingual Evaluation Understudy의 약어라고 한다
Precision, 정밀도라고 기계 번역 단어가 인간 번역에 나타나는 비율을 판단한 개념도 있다
그런데 번역이 The the the the 같은 식이어도 나타 날 수 있으니, 좋은 방법은 아니다
최대 문장에서 나타난 개수를 통해 제한을 할 수 있다다음으로 bigram의 Bleu 점수 정의를 보자
bigram은 나란히 나타나는 단어를 의미한다
이런 예시를 생각 해보자 아래 모델의 아웃풋에서 바이그램은 the cat, cat the, the cat, cat on, on the, the mat이 있다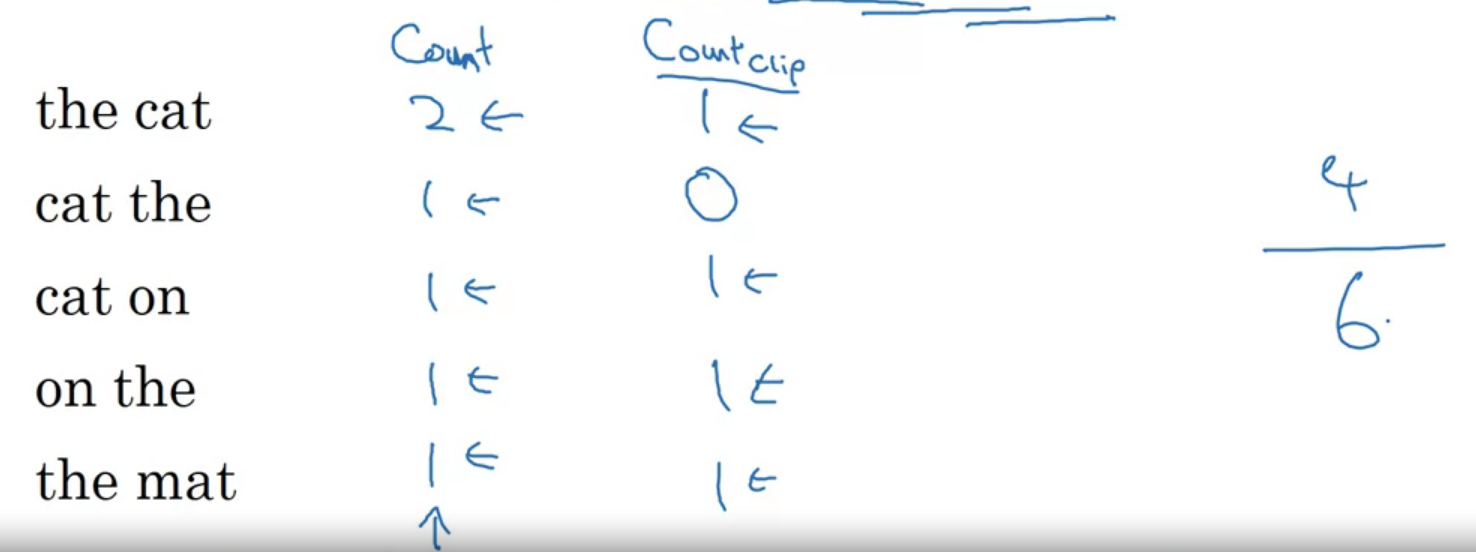
모델에서 숫자, 위 예시에서 최대 등장 횟수를 세면 위와 같다 각각을 sum 해주면 점수가 된다
구체적으론 아래 식이다
\(P_1 = {sum_{unigrams in \hat{y}}count_{clip}(unigram)\over sum_{unigrams in \hat{y}}count(unigram)}\)
P의 첨자 1은 유니그람이란 의미다
N-gram이라면 1 대신 n, unigram 대신 n-gram이 된다 (n은 연속된 단어의 수, unigram은 2개)
기계 번역이 예시와 동일하면 P 값은 1이 된다
\(P_n\)을 하더라도, 문장 길이에 Bleu 점수가 너무 많은 영향을 받을 수 있다
이를 BP(Brevity Penalty)로 짧은 번역을 억제한다
MT_output_length가 reference_output_length 보다 길다면 1,
아니면 exp(1 - reference_output_length/MT_output_length) 값을 가진다
Attention Model Intuition
지금까진 인코더-디코더 형식의 아키텍처를 사용했다
attention model이라는 수정사항이 있는데 무엇인지 알아보자
기존 RNN 아키텍처는 문장이 짧아도 이해하기 어려워 Bleu score 가 낮고
문장이 길어도 네트워크가 기억하기 어려워 점수가 좋지 않았다
사람과 더 비슷하게, 문장의 일부만 보고 번역하는 어텐션 모델을 알아보자
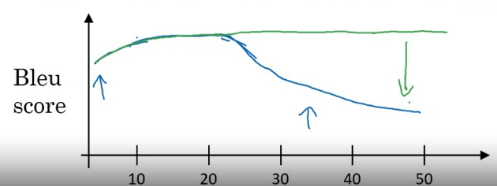
파랑색은 기존, 초록은 어텐션 모델 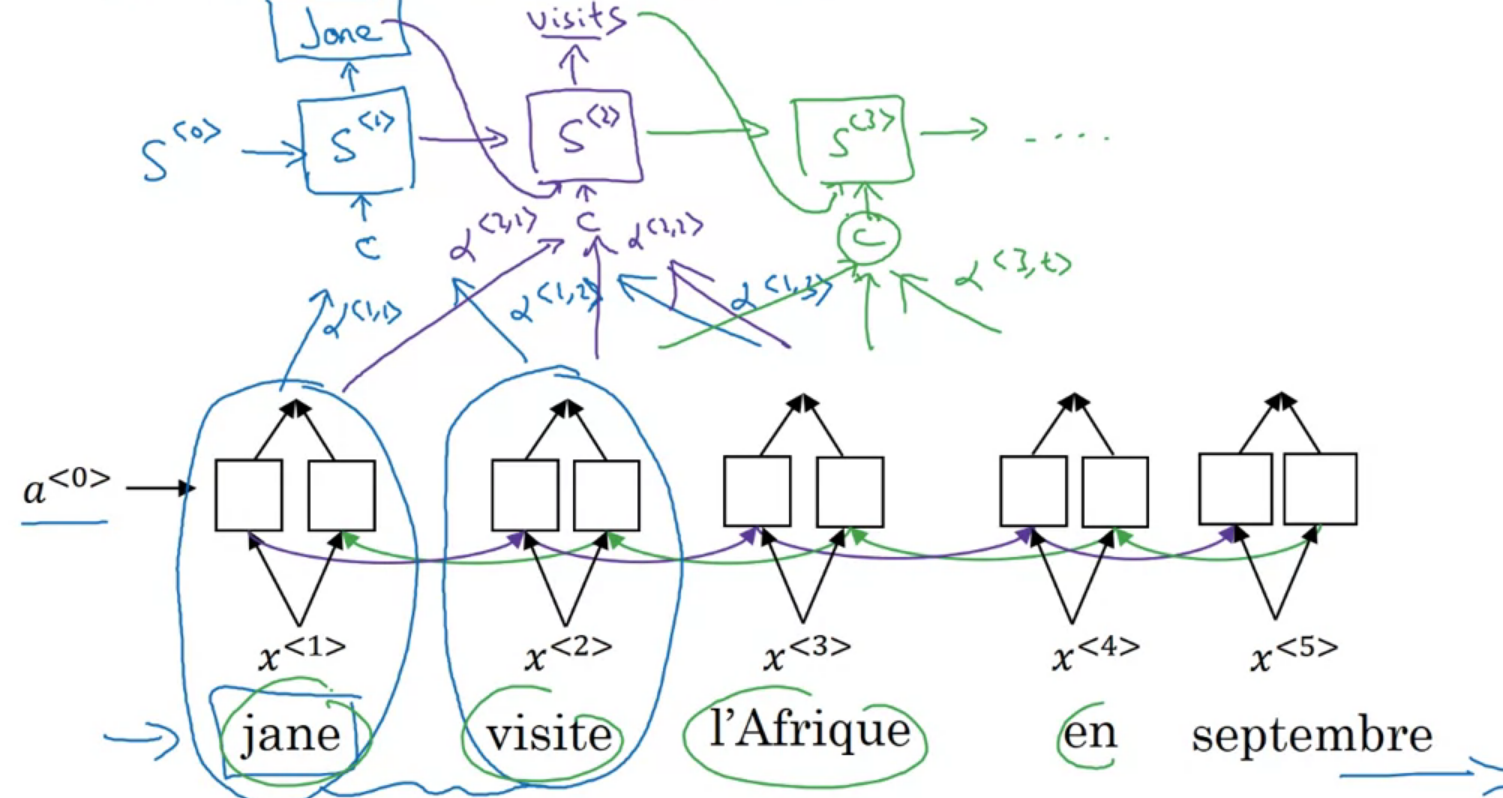
그림이 좀 복잡하다 문장을 읽으며 번역의 첫 단어를 원문의 첫 단어에 얼마나 관심을 기울일지 가중치를 구하고
이를 모아서 단어를 구하는 느낌이라고 한다
아래에서 자세히 알아보자
Attention Model
어텐션 모델은 사람이 번역하는 것처럼, 문장 일부에 집중할 수 있도록 만들어준다
양방향 RNN (GRU or LSTM)

위와 동일한 그림이다 순방향 역방향 활성을 합쳐서 \(a^{<t`>}\)라고 하자
각 단어에 신경을 기울이는 정도(\(\alpha\))를 합치면 1이 되어야 한다
\(\alpha^{<t,t`>}\) = \(y^{<t>}\)에 \(a^{<t`>}\)가 영향을 주는 정도

그렇다고 한다 어텐션의 아이디어는 이미지 캡쳐링에도 이용된다고 한다
Speech Recognition
Seq2Seq 모델이라는 매우 정확한 음성 인식 모델이 있다고 한다
먼저 음성 인식 문제는 오디오 클립을 글로 옮기는 문제를 말한다
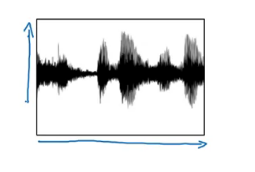
가로는 시간, 세로는 공기압 사람은 주파수에 따라 소리를 들을 수 있기에 전처리를 해준다

세로는 주파수고 세기를 색으로 나타낸다 과거에는 음소 기반으로 음성 인식 모델을 만들곤 했다
그러나 이제는 end-to-end 딥러닝을 이용한다
이를 위해 충분히 큰 데이터 세트와 모델이 필요하다
이런 음성 인식 모델엔 어텐션 모델을 사용할 수도 있다
또 다른 방법으로는 CTC cost (COnnectionist temporal classification)을 사용하는 것이라 한다
\(T_x = T_y\)인 모델 그림으로 살펴보자
보통 LSTM GRU 보다 복잡한 모델을 사용한다고 한다
실제로는 오디오 입력 \(T_x\)가 대부분 더 크다고 한다
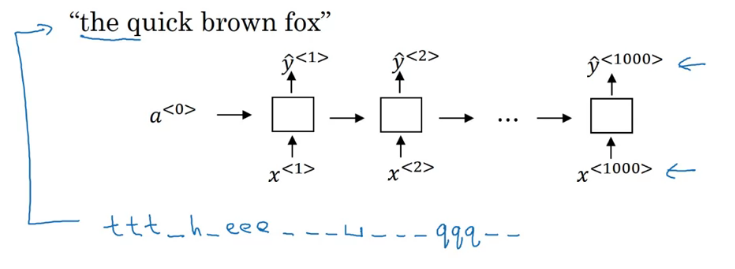
파란색 입력이 들어왔다고 생각해보자
CTC cost 함수의 규칙은 공백으로 구분되지 않은 중복 문자를 제거한다
space와 blank는 서로 다른 기호다!
즉 위의 문장에서 중복을 제거하면 "the q"가 된다
그런가 보다 하자
Trigger Word Detection
음성 인식이 발달함에 따라 목소리를 듣고 작동을 시작하는 시스템이 개발되고 있다이들을 trigger word system 이라고 한다헤이 시리, 오케이 구글, 하이 빅스비 같은 친구들이다최신까지도 발전되고 있기에 뭔가 가장 나은 알고리즘이다! 이런건 없다고 한다RNN을 만들고 모델에 넣어 단어가 언급되는 순간을 1 lable로 나머지는 0으로 하는 방법이 있다고 한다조금 핵 느낌으로 구간에 레이블 1을 주면 더 잘 작동한다고 한다
'Google ML Bootcamp 2022 > Coursera mission' 카테고리의 다른 글
Sequence Models - 4 week (2) 2022.08.16 Sequence Models - 2 week (0) 2022.08.10 Sequence Models - 1 week (0) 2022.08.07 Convolutional Neural Networks - 4 week (0) 2022.08.02 Convolutional Neural Networks - 3 week 실습 (0) 2022.07.31